Sichtbarkeit im großen Maßstab: wie Figma die Exposition sensibler Daten erkennt



Sicherheitsherausforderungen in großem Maßstab zu lösen erfordert ebenso viel Kreativität wie Strenge. Um das Risiko der Offenlegung sensibler Daten zu verringern, haben wir Response Sampling entwickelt: eine leichtgewichtige Echtzeit-Kontrolle, die ausgehende Antworten überwacht, den Zugriff validiert und ein Frühwarnsystem für unsere Produkte bereitstellt.
Sichtbarkeit im großen Maßstab: wie Figma die Exposition sensibler Daten erkennt teilen
Illustrationen von Jose Flores
Die programmgesteuerte Verhinderung der Offenlegung sensibler Daten ist eine der komplexeren Herausforderungen im Bereich der Sicherheit. Die Art und Weise moderner, verteilter Systeme bedeutet, dass Daten durch komplizierte und manchmal unvorhersehbare Pfade wandern können – über Dienste, durch Serialisierungsebenen und in Kontexte, in denen ihre Anwesenheit nicht immer offensichtlich ist. Diese Art von Problemen kann sich auf subtile Weise manifestieren: ein Endpunkt, der mehr Daten zurückgibt als beabsichtigt, ein alter Codepfad, der eine Berechtigungsprüfung überspringt, oder eine fehlende Validierung, die es Benutzer*innen ermöglicht, Ressourcen zu sehen, die sie nicht sehen sollten. Im Bereich der Sicherheit sind dies oft Formen von Autorisierungsfehlern oder unbeabsichtigtem Datenüberfluss – kleine Fehler, die im großen Maßstab große Auswirkungen auf Privatsphäre und Vertrauen haben können.
Um diese Herausforderung direkt bei Figma anzugehen, mussten wir ein Überwachungssystem entwickeln, das sowohl als Sicherheitsnetz als auch als Frühwarnsystem fungiert. Es sollte Expositionen in der Staging-Phase auffangen, bevor sie jemals die Produktion erreichen, und weiterhin unerwartete Regressionen überwachen, sobald sie bereitgestellt sind. Das bedeutete, etwas zu entwickeln, das präzise genug ist, um vertrauenswürdig zu sein, und ausgedehnt genug, um in vielen verschiedenen Teilen des Produkts wertvoll zu sein.
Wir freuen uns, unsere Erfahrung beim Aufbau von Response Sampling zu teilen, einem System, das entwickelt wurde, um potenzielle sensible Datenlecks in Echtzeit zu erkennen. Indem Response Sampling kontinuierliche Sichtbarkeit über die Daten, die unsere Dienste verlassen, bietet, gibt es unseren Teams die Möglichkeit, Probleme schnell zu untersuchen und zu beheben, was das Risiko einer Exposition verringert und unser Vertrauen in den Umgang mit Daten verbessert.
Wir sind dieses Problem mit einer Plattform-Sicherheitsmentalität angegangen – indem wir unsere Anwendungsoberflächen wie Infrastruktur behandelt und kontinuierliche Überwachungs- und Erkennungskontrollen darauf geschichtet haben. Durch die Anwendung von Techniken, die normalerweise für niedrigere Systeme reserviert sind, auf unsere Anwendungsebene konnten wir eine kontinuierliche Sichtbarkeit darüber gewinnen, wie sich Daten durch unsere Produkte bewegen, ohne die Entwicklung zu verlangsamen.
Das Problem identifizieren: Einblick in verborgene Risiken
Bei Figma nehmen wir Berechtigungen und Autorisierungen ernst. Im Laufe der Jahre haben wir in stabile präventive Kontrollen investiert, wie zum Beispiel PermissionsV2, unser fein abgestuftes Autorisierungsframework, sowie in kontinuierliche Tests durch negative Einheitstests, End-to-End-Tests in der Staging- und Produktionsphase und laufende Sicherheitsüberprüfungsprogramme (einschließlich unseres Bug-Bounty-Programms und regelmäßiger Penetrationstests). Diese Systeme geben uns großes Vertrauen in unsere Zugriffsgrenzen und bilden die Grundlage dafür, wie wir die Offenlegung sensibler Daten verhindern.

Mehr erfahren darüber, wie wir PermissionsV2 erstellt haben.
Offenlegung sensibler Daten ist eine Sicherheitslücke, bei der vertrauliche oder geschützte Informationen unbeabsichtigt für Parteien zugänglich gemacht werden, die keinen Zugang haben sollten, was das Risiko von Missbrauch oder Vertrauensverlust erhöht.
Aber präventive Maßnahmen und Tests allein können nicht jeden Edge Case abfangen. Da unsere Produkte und unsere Infrastruktur in ihrer Komplexität zugenommen haben, ist das Risiko subtiler Ungenauigkeiten oder unerwarteter Flows natürlich gestiegen. Selbst gut gestaltete Systeme können Überraschungen produzieren, wenn Dienste auf neue Weise interagieren oder wenn bestehende Wege anders als erwartet funktionieren.
Angesichts der Bedeutung des Datenschutzes für Figma wollten wir eine weitere Verteidigungsebene hinzufügen, die sich auf Erkennung und Beobachtbarkeit konzentriert. Unser Ziel war es, ein System zu entwickeln, das kontinuierlich validieren kann, dass unsere präventiven Kontrollen wie beabsichtigt funktionieren und uns helfen, Anomalien frühzeitig zu erkennen, bevor sie die Produktion beeinträchtigen könnten.
Um das möglich zu machen, brauchten wir ein System, das Folgendes konnte:
- Kontinuierlich die potenzielle Exposition beobachten, unabhängig davon, wo im Produkt sie aufgetreten ist.
- Umsetzbare Insights bereitstellen, die es uns ermöglichen, Probleme frühzeitig zu beheben, idealerweise bevor sie in die Produktion gelangen.
- Aktiv in der Produktion bleiben, um eine zusätzliche Ebene der Verteidigung zu haben, die Regressionen in Echtzeit erkennt.
Diese Ziele bildeten die Grundlage unseres Ansatzes und leiteten uns dabei, wie wir die Erkennungsbreite, den Leistungseinfluss und die betriebliche Wartbarkeit ausbalancierten.
Schritt 1: Aufbau von Antwortentnahmen für Dateiidentifikatoren
Bevor wir Datenexpositionen programmatisch erkennen konnten, mussten wir zunächst entscheiden, was als sensibel zählt. Nicht jedes Feld in einer API-Antwort birgt ein Risiko, daher begannen wir mit einem klar definierten Typ – Dateikennungen –, bei dem Sensibilität und Zugriffsregeln bereits klar waren. Dateikennungen in Figma sind die einzigartigen Token in jeder Datei-URL, deren Einbindung sie mit spezifischen Zugriffskontrollen verknüpft. Da sie hochentropische Token mit einem bekannten Zeichensatz und einer konsistenten Länge sind, lassen sich Dateikennungen leicht in Textströmen erkennen. Das machte sie zu einem praktischen Ausgangspunkt zur Erkennung von Autorisierungs-Bugs und zum Aufbau der Infrastruktur, die später eine breitere Reaktionsstichprobe unterstützen würde, sobald eine systematische Definition von sensiblen Daten verfügbar wurde.

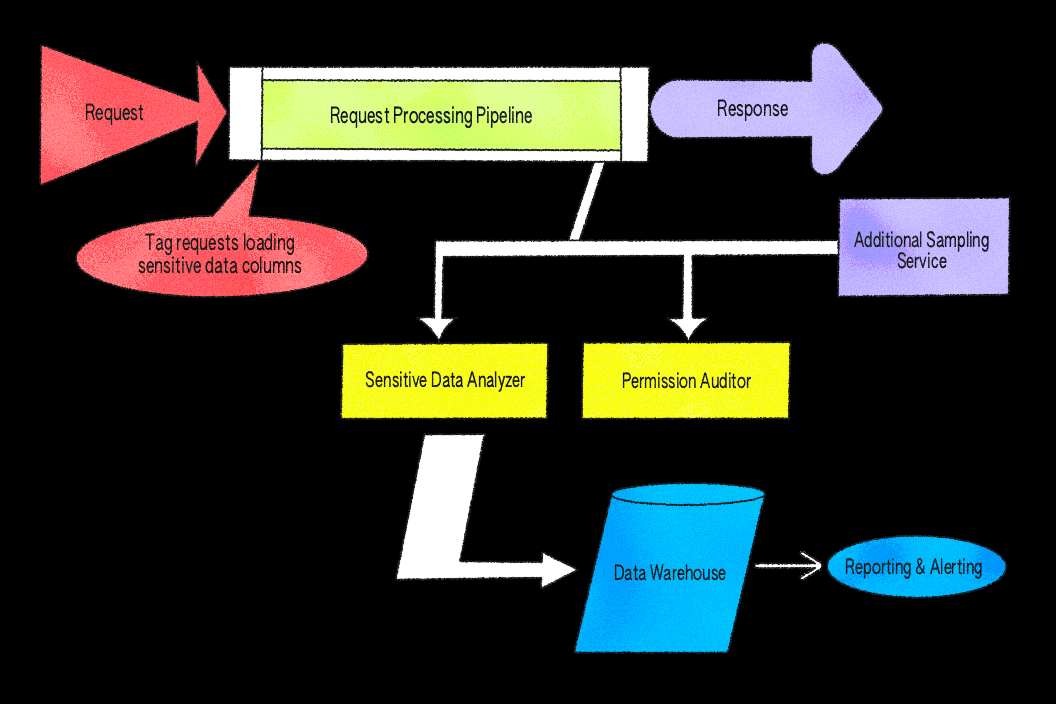
Unsere anfängliche Implementierung konzentrierte sich auf diesen Datentyp und die damit verbundenen Berechtigungsprüfungen. Die Idee war einfach, aber kraftvoll: Eine kleine Teilmenge von Antworten wichtiger Dienste zu überprüfen, nach mit Dateien verknüpften Identifikatoren zu scannen und zu überprüfen, ob die anfragenden Benutzer*innen die Berechtigung hatte, auf jeden Wert zuzugreifen. Das Sampling erfolgt zufällig mit einer konfigurierbaren Rate über Anfragepfade hinweg, was es uns ermöglicht, die Abdeckung zu steuern und die Überkopfkosten zu begrenzen, während dennoch repräsentative Ergebnisse aufgezeigt werden.
Wir haben das System als Middleware in unserem Ruby-Anwendungsserver aufgebaut, weil es direkten Zugriff auf das authentifizierte Benutzer*innen-Objekt, den vollständigen API-Antwortkörper und unser internes Berechtigungssystem, PermissionsV2, bietet. Dies macht es einfach, Antwortdaten zu überprüfen und Berechtigungen an einem Ort zu bewerten. Während wir ähnliche Prüfungen auf einer Proxy-Ebene wie Envoy hätten implementieren können, würde dies die benutzer*innenkontextbezogenen Berechtigungsbewertungen, die in unserer Architektur erforderlich sind, erheblich erschweren.
Wir haben Response Sampling mit einem after-Block und asynchronen Jobs implementiert. Der after-Filter ist ein eingebauter Hook, der automatisch nach Abschluss jeder Anfrage läuft und uns einen konsistenten Ort bietet, um Antworten zu überprüfen, bevor sie an den Client zurückgesendet werden. Der Filter inspiziert berechtigte Antworten gemäß den konfigurierten Stichprobenraten und analysiert JSON-Körper, um Datei-IDs zu extrahieren. Wenn ein relevantes Identifikationsmerkmal gefunden wird, stellt das System asynchrone Jobs in die Warteschlange, um Berechtigungen zu überprüfen. Um Fehlalarme zu reduzieren, wendet die Verifikationslogik Regeln an, die bekannte sichere Fälle berücksichtigen und sicherstellen, dass nur unerwartete Ergebnisse zur Überprüfung angezeigt werden. All dies ist nicht blockierend – wenn das Sampling oder die Verifizierung fehlschlägt, wird die Anfrage trotzdem normal abgeschlossen und Fehler werden zur Überwachung protokolliert.
Ein interner Endpunkt ermöglicht es anderen Diensten, wie LiveGraph, unserem Echtzeit-Datenabfragedienst, der die Zusammenarbeitserfahrungen synchronisiert, ihre eigenen Stichprobendaten einzureichen und die Verarbeitungspipeline erneut zu nutzen. Nachdem eine Antwort erzeugt wurde, führt LiveGraph einen leichten API-Aufruf an diesen Endpunkt aus, sodass es von Response Sampling profitieren kann, ohne seinen Echtzeit-Flow zu belasten. Um die Leistung vorhersehbar zu halten, wird das Sampling in LiveGraph durch Konfiguration und Ratenbegrenzung gesteuert. Ergebnisse teilen dasselbe Schema und denselben Protokollierungspfad wie andere Dienste, sodass die Ergebnisse in unserem Analytics-Warehouse und unseren Triage-Dashboards vereinheitlicht sind, was es den Bereitschaftsingenieuren erleichtert, Warnungen unabhängig von ihrer Quelle zu interpretieren.

Lies mehr darüber, wie wir LiveGraph entwickelt haben.
Wir haben diese Logik direkt in die Einbindung unserer API-Infrastruktur integriert, sodass sie sowohl im Staging- als auch im Produktionstraffic ausgeführt werden kann. Die Sampling-Raten wurden so abgestimmt, dass genügend Abdeckung für aussagekräftige Ergebnisse erfasst wurde, ohne merkliche Latenzzeiten einzuführen, und alle Überprüfungen wurden asynchron durchgeführt, um den Anfrage-Antwort-Zyklus nicht zu verlangsamen. Zusätzlich wurde eine Ratenbegrenzung eingeführt, um zu verhindern, dass die Verarbeitungspipeline überlastet wird, und um übermäßigen Ressourcenverbrauch zu vermeiden.
Dieser Ansatz begann sofort, wertvolle Insights zu enthüllen. Innerhalb weniger Tage nach der Einführung brachte Response Sampling subtile Fälle ans Licht, in denen dateibezogene Identifikatoren unnötigerweise in bestimmten Antworten zurückgegeben wurden, was zu einem besseren Filter führte. Es zeigte auch Wege auf, bei denen bestimmte Dateien die Berechtigungsprüfungen vollständig umgingen, sodass wir diese Lücken schließen und unsere allgemeinen Zugriffskontrollen stärken konnten.
Der erste Schritt bewies das Konzept, aber sein Umfang war begrenzt. Dateiidentifikatoren sind wichtig, aber sie repräsentieren nur eine Kategorie von sensiblen Informationen, die wir schützen müssen.
Schritt 2: Erhöhung der Sichtbarkeit durch erweitertes Response Sampling
Auf der Grundlage machten wir uns daran, die Reichweite des Systems zu erweitern. Die anfängliche Implementierung bewies, dass Response Sampling echte Autorisierungsprobleme effizient erkennen konnte, war jedoch auf einen einzelnen Datentyp beschränkt. Die nächste Herausforderung bestand darin, denselben Ansatz auf jedes sensible Feld zu skalieren – im Wesentlichen dem System beizubringen, was „sensibel“ in unseren Produkten bedeutet.
Erweitertes Antwort-Sampling, intern liebevoll „Fancy Response Sampling“ genannt, erweiterte die gleichen Sampling-Prinzipien auf alle sensiblen Daten, indem es mit FigTag, unserem internen Datenkategorisierungstool, integriert wurde.

FigTag funktioniert, indem jede Datenbanksäule mit einer Kategorie annotiert wird, die ihre Sensibilität und beabsichtigte Nutzung beschreibt. Diese Annotationen werden in einem zentralen Schema gespeichert und in unser Data Warehouse übertragen, was es einfach macht, die Sensibilität einer Spalte zur Abfragezeit zu bestimmen. Eine dieser Kategorien, banned_from_clients, dient als unser Signal für Sensibilität und markiert Felder, die unter normalen Umständen in API-Antworten nicht zurückgegeben werden dürfen (zum Beispiel sicherheitsrelevante Kennungen, Abrechnungsdetails und andere PII).
Durch die Integration in FigTag können wir eine Teilmenge von Antworten, die beliebige sensible Felder enthalten, über alle unsere Anwendungsserver-API-Endpunkte hinweg abfragen. Wenn ein Datenbanksatz mit einer als banned_from_clients markierten Spalte in die Anwendung geladen wird (in unserem Fall über ein ActiveRecord-Modell, die Objektrelationale Mapping-Ebene, die in unserer Ruby-Anwendung verwendet wird), zeichnet ein Rückruf seinen Wert in den Anfrage-lokalen Speicher auf. Bei Sample-Anfragen wird dadurch sichergestellt, dass nur Werte verfolgt werden, die während der Anfrage tatsächlich abgerufen werden, um unnötigen Overhead zu vermeiden.
Sobald die Antwort generiert ist, überprüft ein after-Filter das serialisierte JSON und vergleicht es mit den aufgezeichneten sensiblen Werten. Wenn in der Antwort sensible Werte erscheinen, wird ein Log erstellt. Wie zuvor fließen die Ergebnisse in unser einheitliches Analytics-Warehouse und Dashboards ein.
Wir haben auch einen flexiblen Prozess zum Erstellen von Zulassungslisten eingeführt, damit Endpunkte mit geplanter, sicherer Offenlegung vom Responce Sampling ausgeschlossen werden können, ohne die Erkennung von wirklich unerwarteten Daten zu beeinträchtigen. Zum Beispiel könnte ein OAuth-Client-Geheimnis absichtlich von einem dedizierten Endpunkt für autorisierte Benutzer*innen zurückgegeben werden, wäre aber ein ernstes Problem, wenn es in nicht verwandten API-Antworten enthalten wäre.
Früherkennung in Aktion
Das erweiterte Response-Sampling-System ist zu einer leistungsstarken Detektionsebene geworden, die subtile Probleme aufdeckt, die alleine durch Codeüberprüfung oder manuelles QA extrem schwer zu erfassen wären. Es hat uns ermöglicht, Risiken proaktiv in der Staging-Phase zu erkennen und schnell auf Produktionsrückschritte zu reagieren. Hier sind ein paar Beispiele:
- Wir haben festgestellt, dass ein lange nicht genutztes Datenfeld unerwartet in bestimmten Antworten auftaucht. Das Team bestätigte die Entdeckung, kategorisierte sie und veröffentlichte schnell eine gezielte Lösung.
- Das System identifizierte Fälle, in denen Daten von verwandten Ressourcen in Antworten enthalten waren, ohne dass dies eindeutig notwendig war, was zu gezielter Aufräumarbeit führte.
- Response Sampling hob Szenarien hervor, in denen wir eine Liste von Ressourcen in einer Antwort zurückgaben, ohne den Zugriff für jedes Element einzeln zu überprüfen, was zu Verbesserungen der Berechtigungsprüfungen führte.
Erlernte Lektionen zum Ausbalancieren von Präzision und Leistung
Der Aufbau solcher Systeme ist eine teamübergreifende Anstrengung bei Figma. Unsere Sicherheitsingenieur*innen coden gemeinsam mit Produkt- und Plattformteams und bringen die gleiche Kreativität und Strenge in Erkennungssysteme ein, die wir auch in Benutzer*innen-orientierte Funktionen einbringen.
Nach Monaten des Aufbaus und Betriebs des Response Sampling haben wir viel darüber gelernt, was es braucht, um ein programmatisches Erkennungssystem zu entwickeln:
- Denke immer an die Leistungseinflüsse: Wir haben festgestellt, dass selbst kleine Mengen an Überwachung Latenzen verursachen können, wenn sie nicht sorgfältig gestaltet sind. Durch das Anpassen der Sampling-Raten und das asynchrone Ausführen von Prüfungen haben wir die benutzer*innenorientierte Leistung beibehalten, während wir dennoch eine bedeutende Sichtbarkeit des Datenverkehrs erreichten.
- Verwalte Fehlalarme (oder sie werden dich verwalten!): Eine hohe Fehlalarmrate kann Teams überwältigen und das Vertrauen in Warnungen verringern. Um dem entgegenzuwirken, haben wir dynamisches Erstellen von Zulassungslisten und rigorose Triage-Workflows implementiert. Das bedeutete, bekannte, sichere Fälle schnell durch Filterung auszuschließen und es Ingenieur*innen zu ermöglichen, sich auf wirklich riskante Funde zu konzentrieren.
- Kontext ist entscheidend: Nicht alle sensiblen Datenexpositionen sind gleichermaßen problematisch. Durch die Verwendung einer dynamischen Konfiguration konnten wir die Erkennungsregeln schnell anpassen, ohne die Dienste neu bereitzustellen. Dies ermöglichte eine nuancierte Behandlung legitimer Anwendungsfälle, während immer noch unnormale oder unerwartete Szenarien markiert wurden.
- Eine mehrschichtige Verteidigung schaffen: Der Betrieb des Systems sowohl in der Entwicklungs- als auch in der Produktionsumgebung gab uns zwei Verteidigungslinien: frühzeitige Erkennung vor der Freigabe und kontinuierliche Überwachung zur Erfassung von Regressionen. Dieser Ansatz der Tiefenverteidigung war entscheidend, um die langfristige Widerstandsfähigkeit zu erhalten.

Der Weg nach vorn
Mit Response Sampling haben wir einen plattform-sicherheitsorientierten Ansatz zur Produktsicherheit angewandt –indem wir kontinuierliches Monitoring und Erkennung auf unsere Anwendungsoberflächen schichten, um Probleme frühzeitig zu erkennen, ohne die Entwicklung zu verlangsamen.
Wir erweitern dieses Framework, um mehr Dienstleistungen und andere Benutzer*innen-Berührungspunkte abzudecken, damit wir potenzielle Gefährdungen in allen wichtigen Interaktionskanälen identifizieren können. Wir planen außerdem, die Abdeckung auf zusätzliche sensible Datenkategorien auszuweiten, einschließlich breiterer Klassen von PII und regulierten Daten, um sicherzustellen, dass unsere Erkennungsfähigkeiten mit den sich entwickelnden Compliance-Anforderungen skalieren.
Um die Effektivität der Antwortstichprobe zu bewahren, während unsere Systeme wachsen, suchen wir nach Möglichkeiten, sie anpassungsfähiger und aufschlussreicher zu machen. Zum Beispiel untersuchen wir feinere Stichprobenkontrollen, um die Ressourcennutzung mit der Sichtbarkeit auszugleichen, automatisierte Sofortmaßnahmen, um Untersuchungen zu beschleunigen, und umfangreichere Berichterstattung, um Trends im Laufe der Zeit sichtbar zu machen. Wenn wir dieses Framework erweitern, bleibt unser Ziel dasselbe: die Daten der Benutzer*innen zu schützen und sicherzustellen, dass jede Figma-Erfahrung schnell, zuverlässig und sicher bleibt.
AppSec-Teams nutzen nicht oft Ansätze aus der Infrastruktur-Sicherheit, aber der Aufbau von Response Sampling zeigte, wie effektiv sie sein können, wenn sie auf die Anwendungsebene angewendet werden. Die kontinuierliche Erkennung näher an die Anwendungsebene zu bringen, half uns, Probleme früher zu finden und schneller darauf zu reagieren – ein Ansatz, von dem wir glauben, dass auch andere Teams profitieren könnten.

Wir stellen Ingenieur*innen ein! Erfahre mehr über das Leben bei Figma und durchsuche unsere offenen Stellen.