



Von mehrtägiger Latenz zu nahezu Echtzeit-Insight: Upgrade der Datenpipeline von Figma




Nach einem exponentiellen Wachstum bei Benutzer*innen und Daten begannen tägliche Synchronisationsaufgaben, Stunden oder sogar Tage zu dauern. So hat der Neubau einer Datenpipeline die Latenz auf nahezu Echtzeit reduziert.
Von mehrtägiger Latenz zu nahezu Echtzeit-Insight: Upgrade der Datenpipeline von Figma teilen
Illustrationen von Cynthia Alfonso
Figma hat sich in den letzten fünf Jahren rasant entwickelt – einschließlich der Einführung von FigJam im Jahr 2021, Dev Mode im Jahr 2023, Figma Make im Jahr 2025 und der vollständigen Lokalisierung, um den brasilianischen, japanischen, spanischen und koreanischen Markt zu bedienen – aber dieses Wachstum bringt Herausforderungen mit sich. Mit der Expansion unserer Benutzer*innenbasis ist auch das Volumen und die Komplexität der Daten gestiegen, die unsere Plattform täglich generiert.
Letztes Jahr haben wir die Insider-Geschichte geteilt, wie unser Datenbankteam unsere Online-Relationsdatenbanken horizontal skaliert hat. Aber unser altes Synchronisationssystem, das dafür verantwortlich ist, Daten von unseren Online-Datenbanken zu unserem analytischen Lagerhaus zu übertragen, das kritische Geschäft Insights liefert, einschließlich der wichtigsten Unternehmens-KPIs, hatte Schwierigkeiten mit der Belastung.

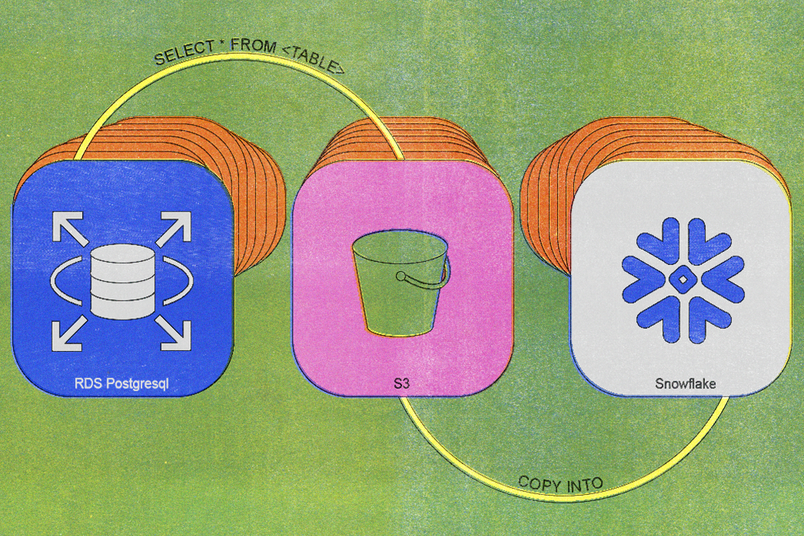
Wir haben unseren ersten Legacy-Synchronisationsprozess im Jahr 2020 aufgebaut, und die Architektur war einfach: Ein täglicher Cron-Job führte eine einfache SELECT * FROM <TABLE> -Abfrage aus, lud die resultierenden Daten auf S3 hoch und importierte diese Daten in Snowflake.
Anfänglich funktionierte dies gut. Als die Tabellen jedoch größer wurden und mehr Einfügungen erforderten, wurden die Einschränkungen des Systems offensichtlich. Bis 2023 dauerten tägliche Synchronisationsaufgaben etwa sechs Stunden, und wir mussten zusätzliche Datenbankreplikate pflegen, um täglich Daten zu exportieren. Unsere größten Tabellen benötigten Synchronisierungszeiten von mehreren Tagen oder mehr.
Letztendlich wurde es fast unmöglich, unsere Daten innerhalb eines angemessenen Zeitrahmens zu synchronisieren, was unsere Fähigkeit, Daten zu analysieren und fundierte Entscheidungen zu treffen, erheblich beeinträchtigte.
Wir haben drei Lösungen evaluiert:
- Beibehaltung unseres Legacy-Synchronisationsprozesses: Dies wurde schnell untragbar, sowohl aufgrund der Synchronisationsverzögerungen als auch weil die Pflege zusätzlicher Datenbank-Replikate jährlich Millionen von Dollar an unnötigen Kosten verursachte.
- Hinzufügen von Parallelisierung als Schnelllösung: Wir zogen in Erwägung, Parallelisierung hinzuzufügen, was es dem Synchronisationsprozess ermöglicht hätte, Vorgänge gleichzeitig durchzuführen, aber dies erwies sich als nicht skalierbar.
- Überarbeiten des gesamten Datenabgleichsprozesses: Dies würde eine größere Investition über einen längeren Zeitraum erfordern, wäre jedoch der skalierbarste Ansatz und der am wahrscheinlichsten von Dauer, da Figma weiter wächst.
Incrementelle Synchronisation ist eine Datenpipeline-Technik, die entwickelt wurde, um analytische Datenbanken effizient auf dem neuesten Stand zu halten, indem sie nur die letzten Änderungen von der Quellendatenbank erfasst und anwendet und nicht wiederholt komplette Datensätze überträgt. Dies reduziert die Datenübertragungszeit und die Ressourcennutzung erheblich.
Beim Betrachten der Optionen wurde unsere Wahl klar: Wir verlagerten unseren Fokus auf den langfristigen Bereich und begannen mit der Arbeit an einer inkrementellen Synchronisierung – eine Lösung, die nachhaltige, effiziente Ergebnisse versprach.
Kaufen vs. Bauen
Um zu funktionieren, erfordert die inkrementelle Synchronisierung Unterstützung für Datenbank-Tabellenschnappschüsse, Change Data Capture (CDC)-Streams und inkrementelles Zusammenführen. Je mehr wir das Potenzial der inkrementellen Synchronisation betrachteten, desto mehr erkannten wir, dass wir es selbst entwickeln müssten. Wir überlegten, eine proprietäre End-to-End-Lösung zu kaufen, aber keine Option erfüllte unsere Bedürfnisse in Bezug auf Flexibilität, Kosten und Skalierbarkeit.
Flexibilität: Viele der von uns gefundenen generischen SQL-kompatiblen Tools nutzten die spezifischen Fähigkeiten der Anbieter nicht effektiv. Die APIs für Amazon Relational Database Service (RDS) für PostgreSQL hätten es uns beispielsweise ermöglicht, Snapshots direkt zu erstellen, ohne den Overhead der Wartung einer separaten Datenbankreplik zu haben, aber die generischen Optionen nutzten dies nicht aus. Wenn wir uns für eine Anbieterlösung entschieden hätten, hätten wir nicht die Flexibilität, unseren Workflow basierend auf der vorhandenen Technologie zu optimieren.
Kosten: Viele Optionen hätten auch auf unserer Ebene erhebliche Prämien gekostet. Als wir unsere Optionen preislich festsetzten, prognostizierten wir, dass proprietäre Lösungen fünf- bis zehnmal mehr kosten würden als eine interne Lösung.
Skalierung: Die Kosten hätten sich gelohnt, wenn diese Werkzeuge skalierbar gewesen wären, aber wir haben festgestellt, dass viele unserer aktuellen und wachsenden Bedürfnisse nicht ausreichend skalierbar waren. Wir haben unseren Legacy-Synchronisationsprozess im Jahr 2020 erstellt und Figma wächst immer noch. Durch den Eigenbau stellen wir sicher, dass wir schnell auf zukünftige Bedürfnisse innovativ reagieren können.
Erstellen und Kombinieren von Komponenten auf niedrigerer Ebene
Durch den Aufbau einer maßgeschneiderten Pipeline konnten wir niedrigere Komponenten finden und kombinieren – entweder Open-Source oder verwaltete Dienste –, die genau mit unseren Infrastrukturanforderungen (und dem Fachwissen unseres Teams) übereinstimmten.
Für Snapshots verwenden wir Amazon RDS, das nach S3 für erste Tabellenkopien exportieren kann. Für CDC verwenden wir Kafka Connect, das effizientes Streaming bietet, sobald es mit einem Snowflake-Verbinder integriert und auf Amazon Managed Streaming für Apache Kafka (MSK) gehostet wird. Für inkrementelles Zusammenführen haben wir benutzerdefinierte Zusammenführungslogik durch Snowflake gespeicherte Prozeduren implementiert und Prozesse über Snowflake-Aufgaben automatisiert.
Eine neue Pipeline-Architektur aufbauen
Bei jedem neuen Projekt erstellen wir einen Umriss der Designprinzipien, die die Arbeit leiten und unsere Ziele sowie Entscheidungen formen. Für dieses Projekt haben wir vier Prinzipien definiert:
- Latenz: Zeit für die Synchronisation von Daten von Anfang bis Ende reduzieren.
- Kosten: Kosten senken und niedrig halten, auch während wir weiter wachsen.
- Compliance: Die Compliance aller relevanten Datenschutzstandards sicherstellen.
- Datenintegrität: Workflows einsetzen, die sicherstellen, dass Daten während des gesamten Lebenszyklus genau, vollständig, konsistent und zuverlässig bleiben.

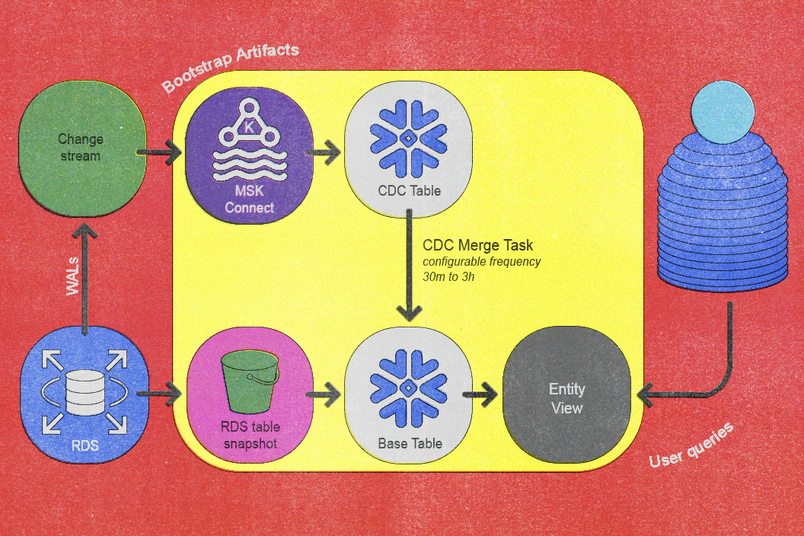
Letztendlich führten diese Prinzipien zu einer neu gestalteten Datenpipeline, die eine inkrementelle Synchronisation über zwei grundlegende Workflows erreicht: einen Bootstrap-Workflow und einen Validierungs-Workflow. Der Bootstrap-Workflow integriert neue Tabellen in die Pipeline, und der Validierungs-Workflow überprüft die Datenkorrektheit, während die Daten in die Pipeline Flow. Zusammen sorgen diese beiden Workflows dafür, dass die Daten effizient in Flows fließen und so konsistent und korrekt wie möglich bleiben.
Bootstrap-Workflow
Unser Onboarding-Prozess zur Integration neuer Tabellen in die Synchronisationspipeline besteht aus den folgenden automatisierten und klar definierten Schritten:
- Der bestehende CDC-Dienst erfasst die neue Tabelle von Postgres und veröffentlicht Ereignisse in den pro Tabelle angelegten Kafka-Themen. Wir haben diesen Schritt mit unserem bestehenden internen CDC-Dienst automatisiert und ihn in die Topologie des Datenbanksystems integriert.
- Wir übertragen den neuesten täglichen Datenbanksnapshot mithilfe des Snapshot-Exportierens von Amazon RDS nach S3 (was je nach Größe der Tabelle langwierig sein kann).
- Sobald der Schnappschuss erfolgreich nach S3 exportiert wurde, importiert die
COPY INTO <table>-Abfrage von Snowflake Daten von S3 in dedizierte, pro Entität ausgelegte Basistabellen von Snowflake. - Ein Snowflake-Sink-Verbinder innerhalb von MSK Connect streamt Kafka-Topic-Inhalte in Snowflakes pro-Entität-CDC-Tabellen, wobei der Kafka-Start-Offset dem Snapshot-Zeitstempel vorausgeht.
- Wir planen eine Snowflake-Aufgabe, um regelmäßig eine benutzerdefinierte
MERGE-Stored-Prozedur auszuführen, die wir entwickelt haben. - Wenn die Synchronisierung ausreichend die jüngsten Änderungen eingeholt hat, erstellen wir eine leichte Ansicht auf der Basistabelle, um den Benutzer*innen die Abfrage zu erleichtern, was die Einführung abschließt.
Wir haben eine Zero-Downtime-Re-Bootstrap-Fähigkeit implementiert, die für das Management von Ereignissen wie der Schema-Evolution entscheidend ist. Dazu haben wir alle Bootstrap-Artefakte versioniert, mit Ausnahme des abschließenden Benutzer*innen-Ansehens, was paralleles Bootstrapping ohne Unterbrechung des laufenden Betriebs ermöglicht. Die Beförderung zur neuen Version erfolgt nahtlos über einen atomaren ansehen-Update-Schritt.
Validierungs-Workflow
Trotz robuster Designs besteht bei Datenpipelines stets das Risiko der Datenkorruption durch Teilfehler, fehlkonfigurierte Komponenten, Bugs oder unerwartete Anomalien in den Quelldaten. Probleme können an verschiedenen Punkten auftreten – von Snapshot-Exporten und CDC-Ereigniserfassungen bis hin zu inkrementellen Zusammenführungen – und können unbeachtete Dateninkonsistenzen oder falsche analytische Ergebnisse verursachen, wenn sie nicht überprüft werden.
Daher ist ein weiterer entscheidender Aspekt der Architektur ein stabiler Validierungs-Workflow, der sich der Überprüfung der Datenkorrektheit widmet und wie folgt funktioniert:
- Klone die Live-Basistabelle, die wir als Quelle bezeichnen.
- Führe den Bootstrap-Workflow aus, den wir explizit konfiguriert haben, um die Basis- und CDC-Tabellen in ein temporäres Schema zu exportieren, das als Ziel bezeichnet wird. Dies läuft, ohne dass automatisierte Zusammenführungen initiiert werden.
- Richte die Quell- und Zielbasistabellen mithilfe der exportierten CDC-Daten auf identische Zeitpunkte aus, um Konsistenz zu gewährleisten.
- Führe präzise Zell-zu-Zell-Vergleiche zwischen Quell- und Zieltabelle durch.
- Erstelle detaillierte Ergebnisse aus diesen Vergleichen und integriere die Ergebnisse in unsere Überwachungs- und Alarmsysteme.
Diese strenge, zellulare und CDC-bewusste Validierung bietet absolutes Vertrauen in die Datenintegrität, was die Zuverlässigkeit vor und nach dem Start des Services erheblich verbessert.
Investition in Automatisierung
Der Erfolg hier wäre ohne Automatisierung nicht möglich gewesen. Die von uns erstellte Pipeline erforderte eine umfangreiche Orchestrierung über zahlreiche Netzwerkaufrufe und Abhängigkeiten hinweg, und wir benötigten sowohl Ad-hoc- als auch geplante Automatisierung, um alles zusammenzubringen.
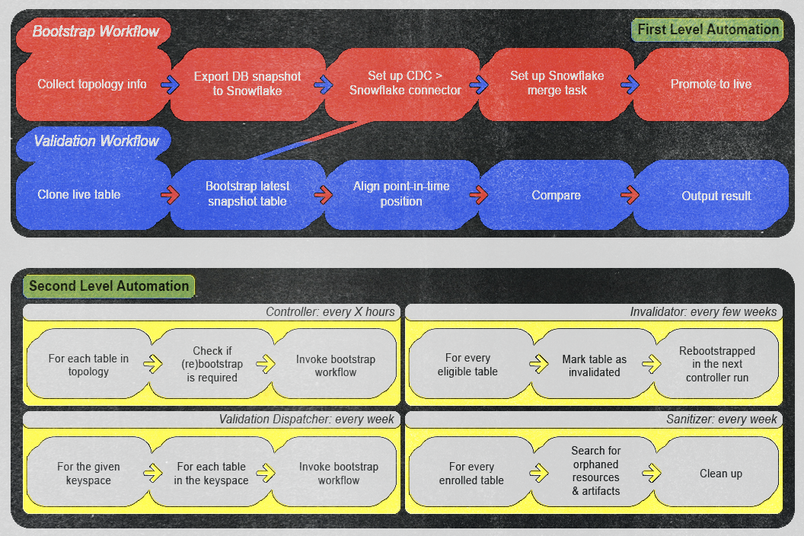
Mihilfe von AWS Step Functions haben wir unsere Automatisierung in zwei Kategorien organisiert:
First-Level-Automatisierung: Diese Kategorie umfasst Workflows, die wir manuell und ad hoc als Auslöser starten können. Wir haben sie so konzipiert, dass sie Bootstrap- oder Validierungsprozesse durch Angabe des Entitätsnamens ausführen. Einmal ausgeführt, erfordern diese Workflows keine manuelle Intervention, es sei denn, das Monitoring erzeugt eine Warnung. Wir haben sichergestellt, dass die Warnungen laut genug sind, um sofortige Maßnahmen des Operators auszulösen – ob es sich nun um einen echten Bug in der Pipeline oder einen Fehlalarm in der Validierungslogik handelt – und bieten klare Maßnahmen, um ein Wiederauftreten zu verhindern und eine hohe betriebliche Effizienz und Zuverlässigkeit zu gewährleisten.
Second-Level-Automatisierung: Diese Kategorie umfasst Workflows, die wir entworfen haben, um First-Level-Automatisierungen basierend auf bestimmten Bedingungen und Zeitplänen aufzurufen. Die erste Ebene übernimmt die Schwerarbeit, und die zweite Ebene überprüft automatisch die aktuellen Zustände, um festzustellen, ob wir einen Auslöser der ersten Ebene aktivieren müssen. Beispiele:
- Ein Controller-Workflow überprüft regelmäßig alle paar Stunden, ob neue Entitäten für das Onboarding oder Re-Bootstrapping verfügbar sind.
- Ein Validierungsdispatcher-Workflow initiiert automatisch Validierungs-Workflows für jede Tabelle auf wöchentlicher Basis.
- Ein Invalidator-Workflow führt wöchentliche Re-Bootstrap-Operationen an jeder Tabelle durch, um die Datenintegrität sicherzustellen.
- Ein Sanitizer-Workflow bereinigt routinemäßig potenziell verwaiste Artefakte jede Woche und hält so eine aufgeräumte und effiziente Umgebung aufrecht.

Wir haben einen aggressiven Ansatz beim Testen gewählt: Eine strenge Automatisierungsroutine in unserer Staging-Umgebung setzt alle Tabellen jede Woche automatisch neu auf, um potenzielle Probleme zu simulieren und proaktiv aufzudecken. Dies zahlte sich aus, als wir nur eine Woche nach Beginn der Tests einen schwerwiegenden Ausfallmode identifizierten. Dieses Problem hätte zu einem vollständigen Ausfall der Sites geführt, der mindestens zwanzig Minuten gedauert hätte, wäre es in die Produktion gelangt. Indem wir dies frühzeitig erkannt haben, stellten wir die Stabilität während tatsächlicher Produktionseinsätze sicher.
Fälle wie dieser unterstützten unseren Glauben, dass volle Automatisierung unser Leitstern sein musste. Selbst wenn einige Workflows herausfordernd oder riskant erschienen, vollständig zu automatisieren, arbeiteten wir schrittweise in Richtung vollständiger Automatisierung, während wir in der Zwischenzeit Teilautomatisierung implementierten. Dieser Ansatz ermöglichte es uns, stetige Verbesserungen der Systemzuverlässigkeit zu erzielen und den betrieblichen Overhead im Laufe der Zeit zu reduzieren.
Die Operationen verliefen nahtlos und es gab keine größeren Vorfälle während und nach dem Start.
Neue Funktionen für bessere Echtzeit-Insights
Als wir zu dieser neuen Architektur übergingen, eröffneten unsere verbesserten Flexibilitäts- und Automatisierungsmöglichkeiten Möglichkeiten zur Entwicklung neuer Funktionen. Drei wesentliche Verbesserungen haben unsere Benutzererfahrung und Entwicklerproduktivität signifikant verbessert.
Konfigurierbare Frische
Basierend auf dem Feedback der Benutzer*innen haben wir die Standard-Zusammenführungsfrequenz auf alle drei Stunden festgelegt, um die grundlegende Frische aller Einheiten gegen die Snowflake-Berechnungskosten abzuwägen. Zusätzlich haben wir konfigurierbare Überschreibungen für Tabellen eingeführt, die häufigere Aktualisierungen erfordern. Zum Beispiel profitierte unsere Abrechnungspipeline erheblich von halbstündigen Überschreibungen, die die gesamte End-to-End-Pipeline-Latenz erheblich reduzierten.
Synchronisieren auf Abruf
Wir können dank unserem Merge-Job-Queue-System jederzeit sicher Zusammenführungen auslösen. Diese erneuerte Sicherheit ermöglichte es uns, ein benutzer*innenfreundliches CLI-Tool einzuführen, das eine manuelle, sofortige Daten-Synchronisation außerhalb des regulären automatisierten Zeitplans ermöglicht. Dies gewährleistet einen rechtzeitigen Zugriff auf aktuelle Online-Datenbankdaten in Snowflake, wann immer dies erforderlich ist.
CDC-Dateninspektion in Snowflake
Da CDC-Daten bereits zu internen Zwecken in Snowflake importiert wurden, haben wir diese Daten den Benutzer*innen zugänglich gemacht, die an tieferen Insights interessiert waren, die die Abfolge von Änderungen untersuchten, die zum Zustand einer Entität geführt haben, nicht nur den aktuellen Zustand dieser Entität. Während der Incident Response bietet diese Funktion eine sichere Offline-Umgebung zum Debuggen unerwarteter Datenbank-Schreibaktivitäten. Zum Beispiel können Entwickler*innen Abfragen wie „rufe alle E-Mail-Einfügungs-/Aktualisierungs-/Löschereignisse für Benutzer*innen innerhalb eines bestimmten Teams in der vergangenen Woche ab“ durchführen. Durch die Nutzung unserer On-Demand-Synchronisierungsfunktion können Entwickler*innen diese Daten nahezu in Echtzeit in Snowflake abfragen. Um den Richtlinien zur Datenaufbewahrung zu entsprechen und ein unbegrenztes Speicherwachstum zu verhindern, werden CDC-Daten nach einem vordefinierten Zeitraum automatisch gelöscht.
Ergebnisse
Dieses Projekt erforderte eine erhebliche Investition an Zeit, Mühe und Ressourcen – aber die Arbeit hat sich gelohnt, mit Ergebnissen, die unsere Erwartungen übertroffen haben.
Verbesserte Datenaktualität
Wir haben die Datenaktualität dramatisch verbessert. Früher waren Daten oft 30 Stunden oder älter. Jetzt sind die Daten drei Stunden oder weniger alt, und die Benutzer*innen haben die Flexibilität, die Aktualität minutengenau zu konfigurieren.
Skalierbare Leistung
Diese Pipeline handhabt jetzt zuverlässig Tabellen, die mehr als zehnmal so groß sind wie zuvor, und liefert konsistente und vorhersehbare Leistung, während Figma weiter wächst.
Entwicklerproduktivität
Neue Tools bringen immer das Potenzial einer Workflow-Störung mit sich, also gaben wir unserem Team Sicherheit, indem wir sie interviewten, um ihre Bedürfnisse zu ermitteln, und die Pipeline in Systeme integrierten, die unser Team gut kannte.
Sobald die Arbeit abgeschlossen war, konnten wir eine signifikante Steigerung der Entwicklerproduktivität zeigen, die sich aus der Reduzierung des Betriebsaufwands und der Ermöglichung von nahezu Echtzeitzugriff auf Onlinedaten innerhalb des Analytics-Warehouses ergab.
Entwickler*innen können jetzt sicher sowohl den aktuellen Status als auch die Änderungshistorie abfragen – frisch innerhalb von Minuten – was ein schnelleres Reagieren auf Vorfälle, sicherere Rollouts und tiefere Insights ermöglicht.
Kosteneffizienz
Früh in der Implementierung priorisierten wir die Unterstützung für Datenbanken mit horizontalen Shards. Diese Unterstützung bot eine hohe Rendite, da die horizontal geshardeten Datenbanken weniger Tabellen hatten, aber mehr Datenbankmaschinen nutzten – jede mit ihrem eigenen Batch-Replikat. Jetzt liefert diese Pipeline jährlich Einsparungen in Millionenhöhe, indem sie die Infrastruktur und Ressourcennutzung intelligent optimiert, redundante Verarbeitungen eliminiert und sich nahtlos mit dem Geschäftswachstum skaliert.
Zukünftige Möglichkeiten
Unsere neue Architektur bietet die Grundlage für mehrere spannende Möglichkeiten, die Datenpipeline weiter auszubauen und zu erweitern.
- Vollständig automatisiertes Onboarding: Derzeit erfordert das Onboarding eine Pull-Anfrage, um Tabellen zu einer Zulassungsliste hinzuzufügen, was Reibung im Onboarding-Prozess erzeugt. Die direkte Integration unserer Datenbanktopologie in die Pipeline würde das Tabellen-Onboarding vollständig automatisieren, die Entwicklererfahrung optimieren und den manuellen Aufwand reduzieren.
- Unterstützung für zeitpunktbezogene Tabellen: Wir könnten die Möglichkeit bieten, Tabellenstatus zu jedem beliebigen Zeitpunkt innerhalb unseres definierten CDC-Aufbewahrungsfensters mittels unserer CDC-Daten abzufragen. Die Implementierung dieser Funktion würde die Fehlersuche, die Vorfallreaktion und die analytische Flexibilität erheblich verbessern.
- Inkrementell aktualisierte Downstream-Modelle: Viele unserer nachgelagerten Analysemodelle werden immer noch mit traditionellen Batch-Prozessen erstellt. Unsere neue Pipeline ermöglicht es uns, diese inkrementell zu aktualisieren, wodurch ihre Effizienz erheblich verbessert wird und die Latenz im gesamten analytischen Workflow reduziert wird.
Diese ehrgeizige Transformation wurde durch das unglaubliche Engagement und die Anstrengung der aktuellen und ehemaligen Mitglieder des Data Infrastructure Team von Figma möglich gemacht: Amadeo Casas, Alex Tian, Brandon Choi, Carter Bian, David Mah, Dorothy Chen, Ebuka Akubilo, Jimmy Xie, Krish Chainani, Merry Song, Michael Wu, Peng Wang, Raunak Agnihotri, Santosh Muthukrishnan, Xinxin Dai, Zubair Saiyed.
Besondere Anerkennung und Dank gebührt auch unseren unterstützenden Partnerteams: Asheesh Laroia, Dylan Visher, Gordon Yoon, Gustavo Angulo Mezerhane, Langston Dziko, Ping-Min Lin, Sammy Steele, Sean Rice, Yazad Khambata.

Wir suchen Ingenieur*innen! Erfahre mehr über das Leben bei Figma undsieh dir unsere offenen Stellen an.